并发与并行概念的区别
首先要搞清楚并行与并发的区别,后续要用到这两个概念。
| 并发(concurrency) | 并行(parallelism) | |
|---|---|---|
| 概念 | 支持多个动作同时出发,并且统一管理 | 支持多个动作同时执行 |
| 多线程 | 是 | 是 |
| 多核 | 单核交替 or 多核同时 | 多核同时 |
| 范畴 | 需求侧 | 实现测 |
| 对立概念 | 单发 | 串行 |
支持并发但不支持并行的例子
一个网站支持并发请求,但是不支持并行处理请求。因此高并发场景下,多个任务还是需要”排队“,按顺序进行处理。
(因为操作系统和硬件的资源很宝贵,所以这是一种效果非常好的处理方式。”使用较少资源做更多事情“的哲学也是指导Go语言设计的哲学。)
支持并行但不支持并发的例子
一个 CPU 核心里的指令解码模块,和加法器,就是并行地处理指令的,但是一个 CPU 核心并不天然支持并发访问,这种叫流水线并行。
正因为并行和并发不是一个范畴的概念,因此原则上他们并
不互斥。然而在通常情况下,人们所说的支持并发的意思是支持并发但不支持并行,这不太严谨,but理解万岁吧~
CPU物理核与逻辑核的概念
谈到高并发就一定会经常提及物理核、逻辑核等概念,这里也一并把他们搞清楚。
CPU数
Linux下输入命令 cat /proc/cpuinfo 看到的 physical id 就是指 CPU 的 id。
个人电脑大多数只有一个 CPU,但是服务器上通常有很多个CPU槽位,可以支持安装多个物理CPU。
物理核数
Linux下输入命令 cat /proc/cpuinfo 看到的 cpu id 就是指物理核的 id。
一个物理核上的逻辑核公用一套ALU、FPU、Cache等组件。
逻辑核数
Linux下输入命令 cat /proc/cpuinfo 看到的 processor 就是指逻辑核的 id。超线程技术可以在一个逻辑核等待指令执行的间隔(等待从cache或内存中获取下一条指令),把时间片分配到另一个逻辑核。高速在这两个逻辑核之间切换,让应用程序感知不到这个间隔,误认为自己是独占了一个核。
《Go IN ACTION》书中描述非Go语言的传统应用程序时没有提及超线程技术,而只是说操作系统会在
处理器上调度线程。实际上他说的处理器就是逻辑核的数量。

线程和进程的概念
进程(process)
当运行一个应用程序的时候,操作系统会为这个应用程序启动一个进程,可以把这个进程看作包含了应用程序在运行中需要用到和维护的各种资源的容器。这些资源包括但不限于:
- 内存地址空间
- 存放代码
- 存放数据
- 句柄
- 文件句柄
- 设备句柄
- 操作系统句柄
- 线程
- 主线程(主线程终止时,应用程序也会终止)
- 子线程
线程(thread)
一个线程是一个执行空间,这个空间会被操作系统调度来运行函数中所写的代码。
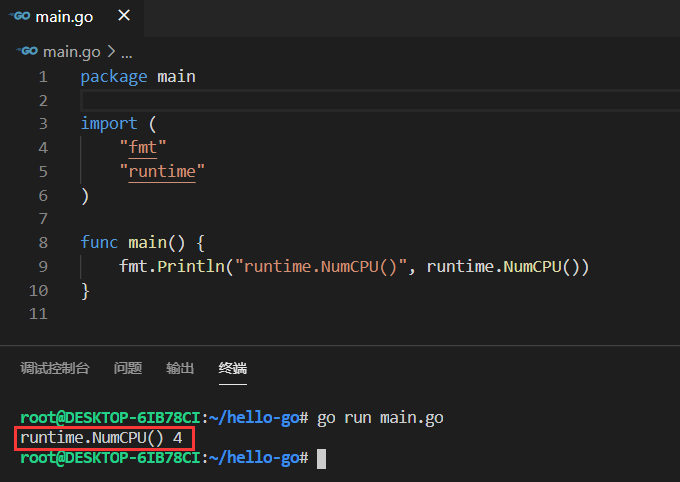
G-P-M模型
操作系统会在处理器上调度线程来运行,而Go语言的运行时会通过调度器(下文简称 Sched)来调度逻辑处理器(下文简称为 P)上调度 goroutine (下文称为 G)来运行。但是 G 并不直接绑定 OS 线程 (下文简称 M)运行,而是由 P(逻辑处理器)来作获取内核线程资源。
在 Go 程序里我们通过下面的图示来展示 G-P-M 模型:
线程(Machine)
M 的个数不定,由Go Runtime调整,最大默认10000个(可通过 runtime/debug 包的 SetMaxThread 来修改)。
逻辑处理器(Processors)
当有多个 P 的时候,Sched会将 G 平等的分到每个 P 上。但是,若想真正实现并行的效果,一定要在多核的机器上运行,否则多线程依然在一个核上运行,达不到并行效果。P 内最重要的三个东西:
- 执行环境 Context
- 内存分配状态
- 任务队列 LRQ
1.5 版本前,默认整个应用程序只分配一个 P(即使只有一个 P,Go也展现了神奇的效率核性能。)
1.5 版本后,默认给每个可用的核分配一个 P,实际由 GOMAXPROCS 确定,个数固定。
Go也是通过运行此语句来设置 P 的数量的:
runtime.GOMAXPROCS(runtime.NumCPU())
协程(Goroutines)
Go 协程 (goroutine) 是指在后台中运行的轻量级执行线程。
Sched管理 G 的策略
任务窃取(work-stealing)策略
每个 P 都有一个 LRQ,用于管理分配给在 P 的上下文中执行的 G,这些 G 轮流被和 P 绑定的 M 进行上下文切换。GRQ 适用于尚未分配给 P 的 G。
Go程序运行时,当每个 P 之间的 G 任务不均衡时,调度器允许从 GRQ,或者其他 P 的 LRQ 中获取 G 执行。
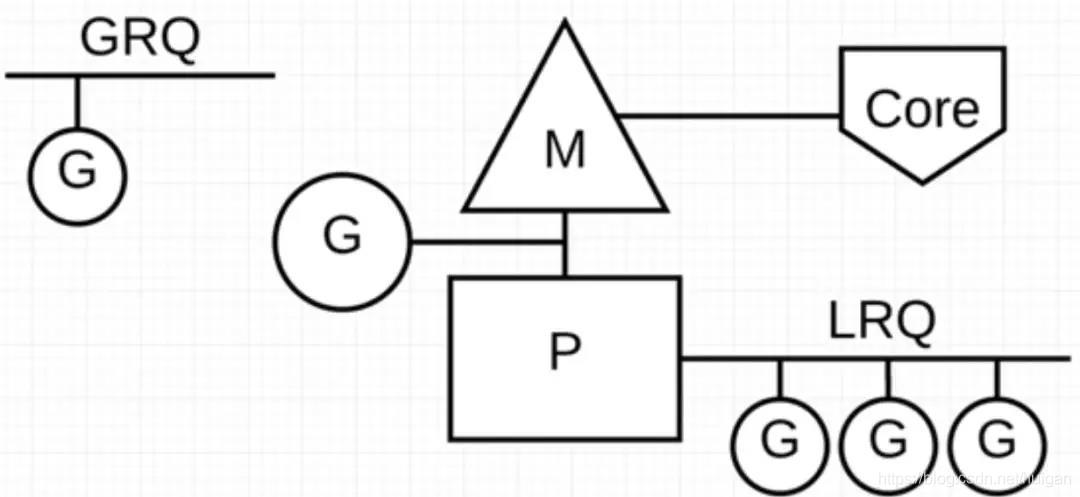
G 执行阻塞的系统调用时(如打开文件)
1、Sched会将这个M与 P 分离,该 M 继续阻塞,等待系统调用返回。
2、与此同时,这个 P 失去了用来运行的 M,所以调度器会再创建一个新的 M,并将其绑定到该 P 上。
3、之后,Sched从 P 的本地运行队列里选择另一个G来运行。
4、一旦被阻塞的系统调用执行完成并返回,对应的 G 会放回到 P 的本地运行队列,而之前的 M 会保存好,以便继续使用。
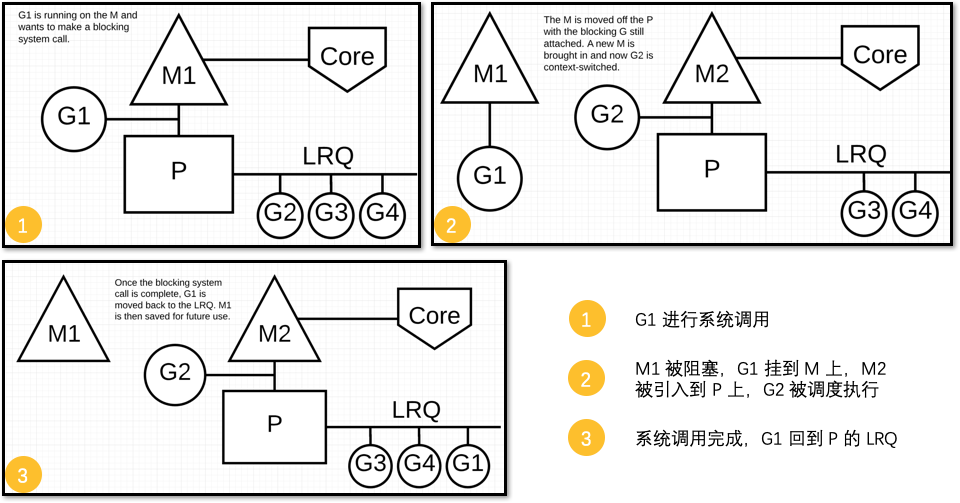
如果一个 G 需要做一个网络I/O调用时
1、Sched会将这个M与 P 分离,并移到继承了网络轮询器的运行时。
2、一旦轮询器提示某个网络读或写的操作已经就绪,对应的 G 就会重新分配到 P 上来完成操作。
参考
https://blog.csdn.net/huigan/article/details/106134937
https://blog.csdn.net/baixiaoshi/article/details/105208141
《Go IN ACTION》
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 nz_nuaa@163.com