
推荐一位宝藏级 B 站 UP 主 ZOMI 酱,此系列即学习 ZOMI 老师的 AI 科普系列视频的总结笔记~
- bilibili 主页: ZOMI酱
- github 主页: chenzomi12
前言
1、Software advances can inspire architecture innovations.
2、Ultimately the marketplace settles architecture debates.
3、Raising the hardware/software interface creates opportunities for architecture innovation.
三句话对计算架构发展黄金十年的总结,来自 David Patterson: A New Golden Age for Computer Architecture
1、软件的进步可以激发硬件架构的创新。
2、市场最终会解决架构的争论。
3、提高硬件和软件之间的接口为架构创新创造了机会。
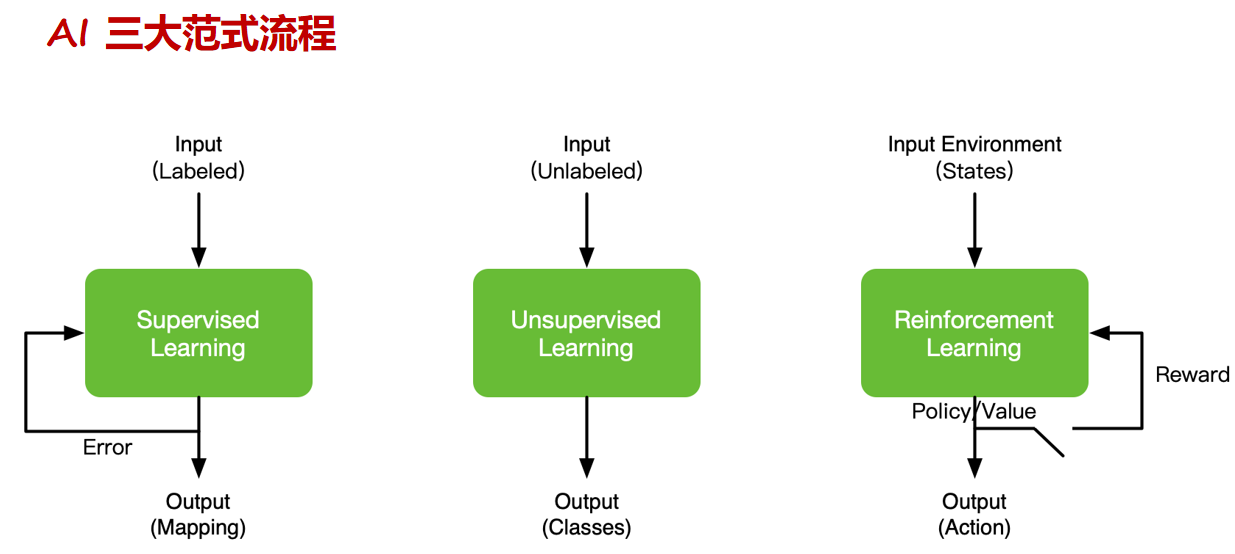
深度学习计算模式
AI 的发展和范式
神经网络主要计算:乘加
multiply and accumulate (MAC) > 90% computation
权重求和计算在 AI 的计算任务中占比超过 90%
神经元 = 权重(Σ)+ 激活函数(f)
网络模型结构设计 & 演进
主流网络模型结构
- 全连接(Fully Connected Layer)
- 卷积层(Convolutional Layer)
- 循环神经网络(Recurrent Layer)
- 注意力机制(Attention Layer)
决定模型规模大小的几个指标
NCHW(N代表数量, C代表channel,H代表高度,W代表宽度)
1、channel
权重Weights,输入Input Feature Map,输出Output Feature Map,的channel数量一致,因此channel大了他们会很大。
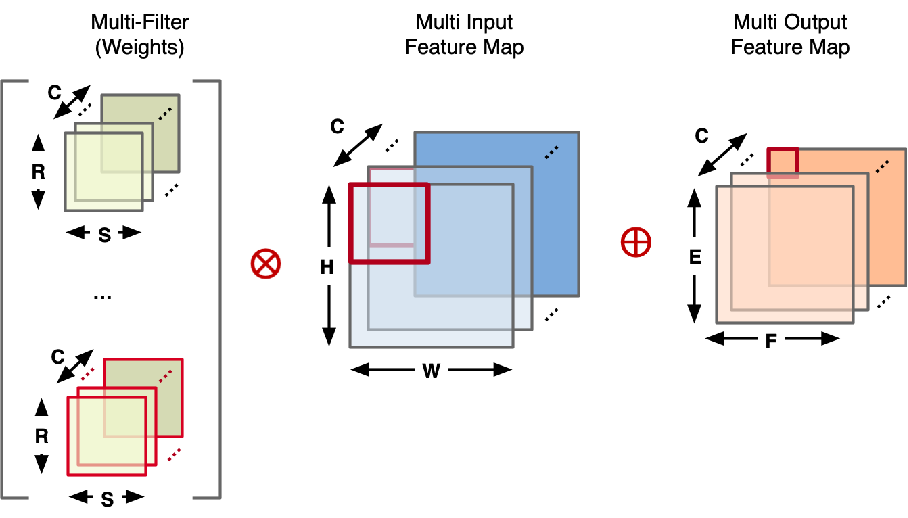
2、batch size
决定 Feature Map 的轮数,对应 NCHW 中的 N。
3、input size
在图像处理中,可以理解为一张图片的大小。
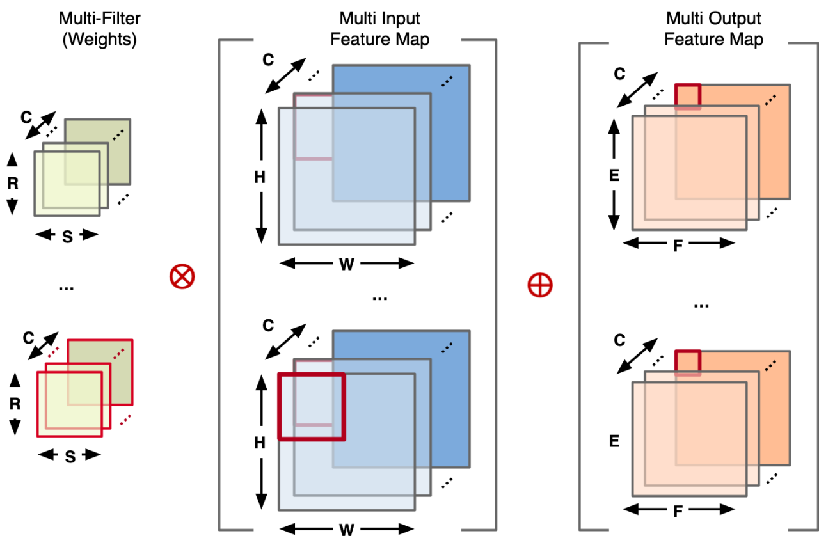
4、Dynamic shape(varies across layer)
所谓动态 shape,即在不同的层中 Feature Map 的长和宽会发生变化。
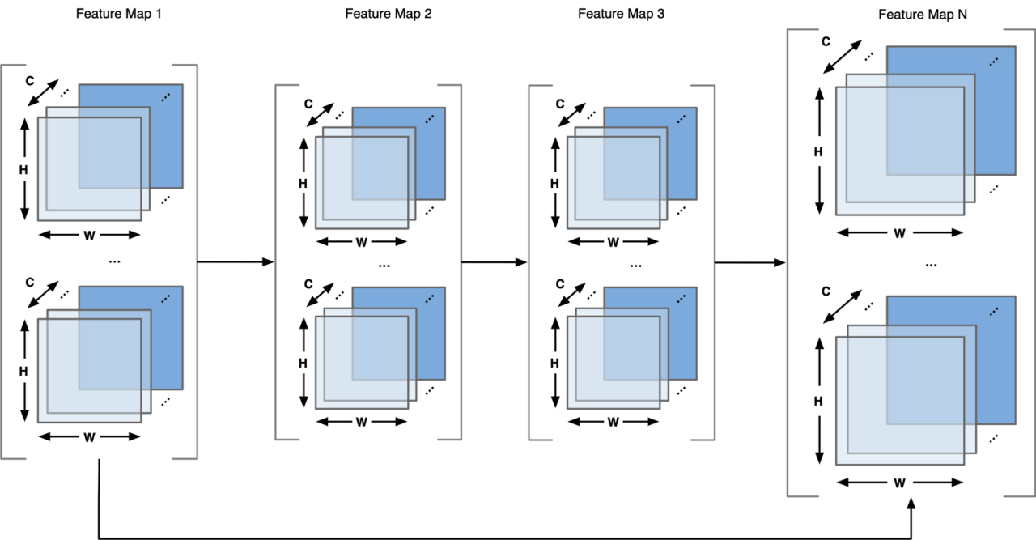
模型量化、网络剪枝
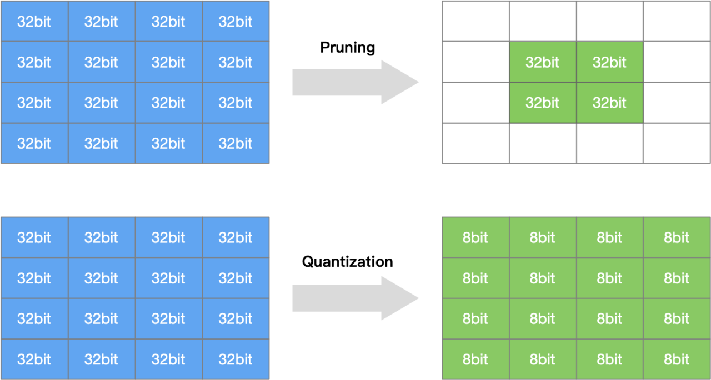
模型量化
是指通过减少权重表示或激活所需的比特数来压缩模型。
- 感知量化训练 Quantization Training
- 减少计算比特位 Reduce number of bits
- 非线性量化 Non-Linear Quantization
- 减少权重计算 Reduce number of unique weights and activations
- Adder Nets 加法网络
- XNOR-Net 异或非网络模型
网络剪枝
研究模型权重中的冗余, 并尝试删除/修剪冗余和非关键的权重。
- 非结构化剪枝(随机剪枝权重 or 神经元)
- 结构化剪枝(对 filter or channel or layer 剪枝)
大模型分布式并行
Data parallelism
- Data parallelism, DP
- Distribution Data Parallel, DDP
- Fully Sharded Data Parallel, FSDP

Model parallelism
- Tensor MP
- Pipeline MP,流水线并行
以 Megatron-LM 为例介绍流水线并行。
Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
Gpipe 模式
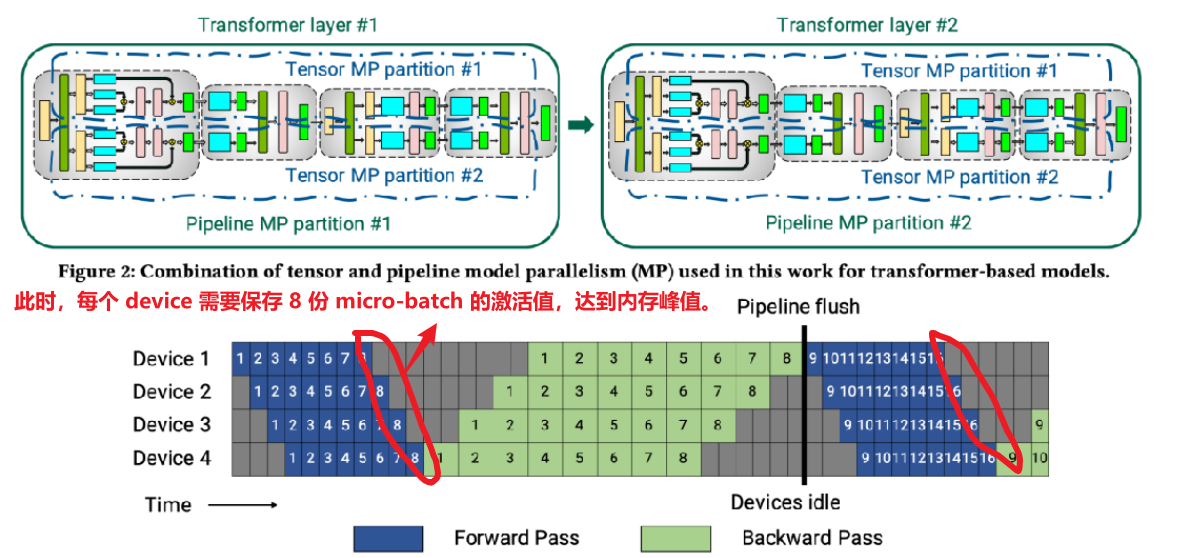
缺点一:空泡率高。假设 m 代表 micro-batch 数量,p 代表 pipeline stages,则要求 m 远大于 p,才能有效降低空泡率。又由于缺点二导致 m 的上限非常有限。
缺点二:内存峰值高。m 个 micro-batch 反向算梯度的过程,都需要之前前向保存的激活值,所以在 m 个 mini-batch 前向结束时,达到内存占用的峰值。Device 内存一定的情况下,m 的上限明显受到限制。
PipeDream 1F1B 模式(非交错 Schedule)
通过合理安排前向和反向过程的顺序,在 step 中间的稳定阶段,形成 1 前向 1 反向 的形式,称为 1F1B 模式。
每个 Device 上最少只需要保存 1 份 micro-batch 的激活值,最多也只需要保存 p 份激活值。
这种模式比 GPipe 更节省内存。然而,它需要和 GPipe 一样的时间来完成一轮计算。
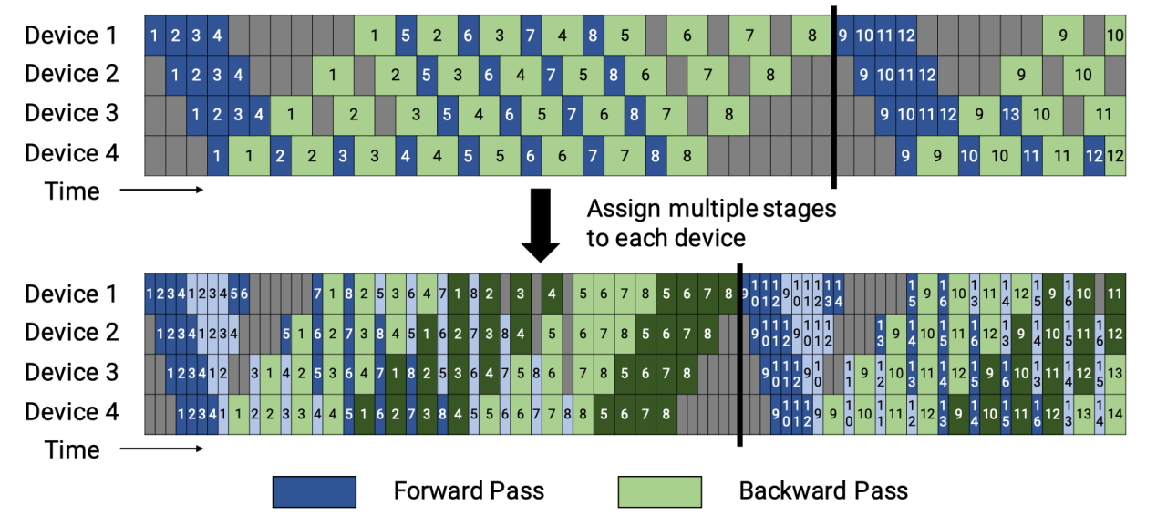
Virtual pipeline 模式(交错 Schedule)
之前设备1拥有层1-4,设备2拥有层5-8,以此类推;但现在设备1有层1,2,9,10,设备2有层3,4,11,12,以此类推。
按照这种方式,Device之间的点对点通信次数(量)直接翻了 virtual_pipeline_stage 倍,但空泡比率降低了。
virtual pipeline 带来的 空泡占比降低 和 step e2e 时间缩短的优势并不是凭空得来,Megatron-2 做出这样改进的本钱主要是在 DGX-box 中,NVLINK 带宽高,通信带来的 overhead 不是很明显。
(要求:micro-batch 的数量是流水线阶段的整数倍。)
参考链接:https://zhuanlan.zhihu.com/p/432969288
参考链接:https://colossalai.org/zh-Hans/docs/features/pipeline_parallel
Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的分布式 AI 模型像构建普通的单 GPU 模型一样简单。我们提供的友好工具可以让您在几行代码内快速开始分布式训练和推理。https://colossalai.org/
思考总结
网络模型结构支持 Architecture
- 支持高维的张量存储与计算
- 神经网络模型的计算逻辑
模型压缩(剪枝&量化) Model Compress
- 提供不同的 bit 位数
- 对于低比特量化相关的研究落地提供 int8/int4 甚至更低的精度
- 在 M-bits and E-bits 之间权衡 Tradeoff (如 TF32/BF16)
- 利用硬件提供稀疏计算
- 硬件上减少 0 值的重复计算
- 减少网络模型对内存的需求,稀疏化网络模型结构
轻量化网络模型 Model Slim
- 复杂卷积计算(小型卷积核,e.g. 1x1 Conv)
- 复用卷积核内存信息(Reuse Convolution)
大模型分布式并行 Foundation Model
- 大内存容量、高速互联带宽
- 专用大模型DSA IP模块,提供低比特快速计算
计算体系与矩阵运算
AI 芯片关键指标
前置知识
常见的四个算力描述单位:
OPS
- OPS(Operations Per Second),1 TOPS 代表处理器每秒进行一万亿次 10^12 计算
- OPS/W 每瓦特运算性能,TOPS/W 评价处理器在1W 功耗下运算能力的性能指标
MACs - Multiply–Accumulate Operations,乘加累积操作。1MACs包含一个乘法操作与一个加法操作,~2FLOPs,通常MACs与FLOPs存在一个2倍的关系。
FLOPs - Floating Point Operations,浮点运算次数,用来衡量模型计算复杂度,常用作神经网络模型速度的间接衡量标准。对于卷积层而言,FLOPs的计算公式如下:
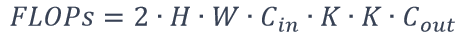
MAC - Memory Access Cost,内存占用量,用来评价模型在运行时的内存占用情况。 1x1 卷积FLOPs为 2⋅H⋅W⋅C_in∙C_out , 其对应MAC为:

Key Metrics
精度 Accuracy
计算精度 (FP32/FP16 etc.)
模型结果精度 (ImageNet 78%)
吞吐量 Throughput
高维张量处理 (high dimension tensor)
实时性能 (30 fps or 20 tokens)
时延 Latency
交互应用程序 (TTA)
能耗 Energy
IOT 设备有限的电池容量
数据中心液冷等大能耗
系统价格 System Cost
硬件自身的价格 $$$
系统集成上下游全栈等成本
易用性 Flexibility
衡量开发效率和开发难度
AI 加速器关键设计点
- 针对 MACs,去掉没有意义的 MACs(增加对系数数据的硬件结构),降低每次 MAC 的计算时间(提升时钟频率,减少指令开销)。
- 针对 PE(Processing Elements),增加 PE 的核心数量,提高 PE 的利用率。
计算性能仿真
PS:此章节同时参考了知乎上介绍 Roofline 模型的一文:Roofline Model与深度学习模型的性能分析
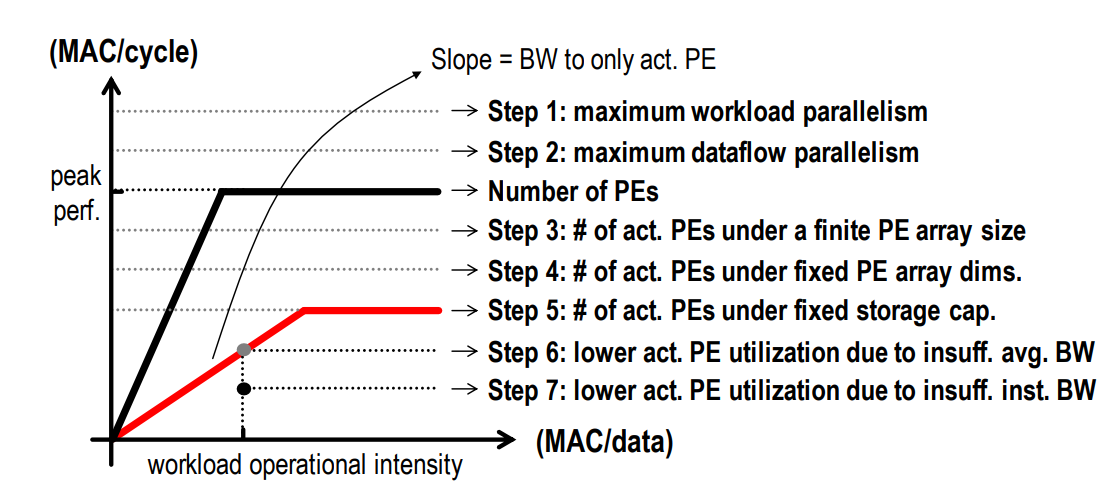
Roofline 模型简介
Roofline 模型是一种面向吞吐量的性能评价模型,它指出在理想情况下,处理器性能的理论上界。
(下文贴图论文原文:Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices)
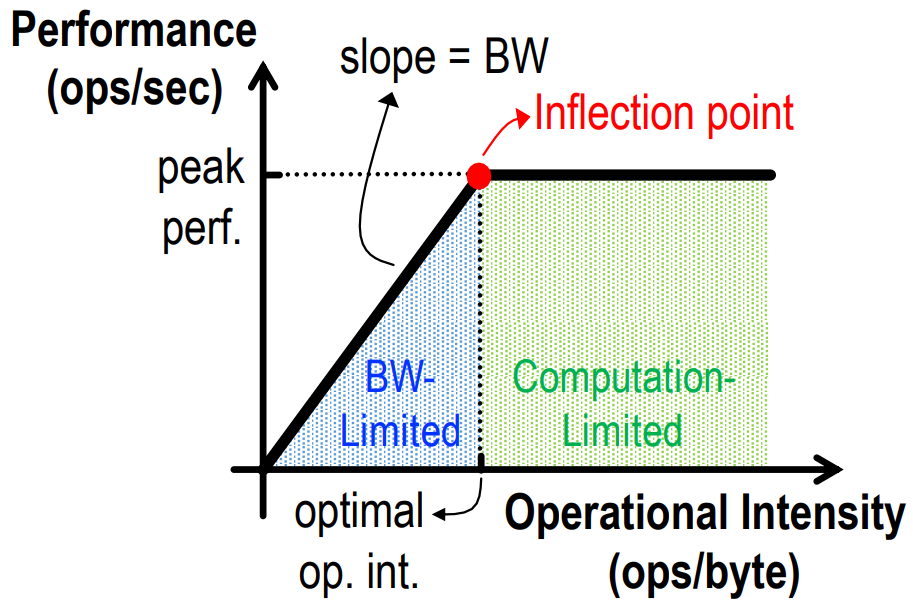
- 横轴代表 计算强度(单位:ops / byte),决定于网络模型的 计算量 和 访存量。
- 纵轴代表 计算性能(单位:ops / sec),其最大值(即 平台算力)决定于芯片 PE 数量。
- 斜率代表 带宽(单位:byte / sec),决定于芯片(芯片内,芯片间)的 带宽。
为了帮助理解,我 yy 了算法工程师和芯片工程师的视角,供参考。
算法工程师视角:
希望训练效率尽可能高,最好性能可以达到芯片的峰值算力,否则相当于没有把芯片的计算力百分百发挥出来浪费了。为了达到这个性能理论最高值,需要想办法提升模型的计算强度。如果很难达到则说明带宽严重受限(即斜率太低),如果轻易达到甚至计算强度远超了峰值算力对应的计算强度则说明芯片算力不足,影响了整个模型的运算性能。
芯片工程师视角:
1、希望峰值算力尽可能高(满足用户模型训练性能要求),又要尽可能减少 PE,成本太高。
2、希望用户的计算强度能比较容易达到峰值算力对应计算强度(降低用户性能调优的难度?),又要尽可能减少 HBM 甚至 L2 Cache,成本太高。
处于右侧(屋顶)
不管模型的计算强度有多大,它的理论性能最大只能等于计算平台的算力。当模型的计算强度大于计算平台的计算强度上限时,模型在当前计算平台处于 Compute-Bound状态,即模型的理论性能受到计算平台算力的限制,无法与计算强度成正比。但这其实并不是一件坏事,因为从充分利用计算平台算力的角度上看,此时模型已经的利用了计算平台的全部算力。可见,计算平台的算力越高模型进入计算瓶颈区域后的理论性能也就越大。
处于左侧(屋檐)
当模型的计算强度小于计算平台的计算强度上限时,由于此时模型位于“房檐”区间,因此模型理论性能的大小完全由计算平台的带宽上限(房檐的斜率)以及模型自身的计算强度所决定,因此这时候就称模型处于 Memory-Bound 状态。可见,在模型处于带宽瓶颈区间的前提下,计算平台的带宽越大(房檐越陡),或者模型的计算强度越大,模型的理论性能可呈线性增长。
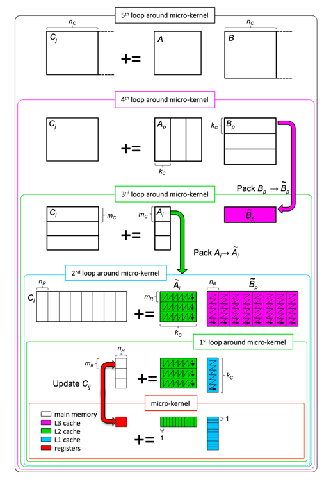
矩阵运算(卷积 Conv -> 矩阵乘 MM)
alias 权重 as 卷积核
矩阵乘分块 Tiling
根据 Cache 大小来对矩阵进行分块 Tiling,最大程度重用数据和利用空间换时间
CPU/GPU 支持矩阵乘的库
// TODO
实现逻辑:
Lib 感知相乘矩阵的 Shape
选择最优的 Kernel 实现来执行
实现方法:
Loop 循环优化 (Loop tiling)
多级缓存 (memory hierarchy)
现有库:Matrix Multiplication (GEMM)
CPU: OpenBLAS, Intel MKL, etc.
GPU: cuBLAS, cuDNN, etc.
卷积代替算法
减少指令开销
比特位宽(bits width)
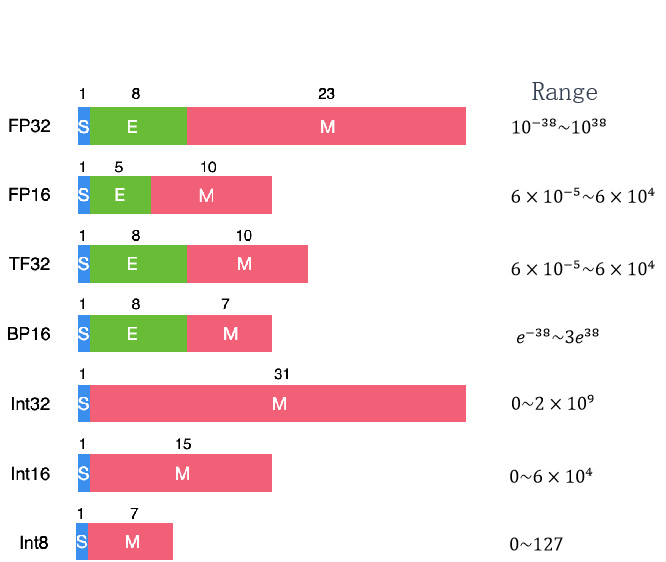
降低精度的好处:
1、对于 MAC 的输入和输出,能够有效减少数据的搬运和存储开销
2、减少 MAC 计算的开销和代价
3、降低位宽对功耗和芯片面积的影响
思考总结
- 精度 Accuracy
- 能够处理各类型的无规则数据 >> 异构平台
- 能够应对复杂网络模型结构 >> 计算冗余性
- 吞吐量 Throughout
- 除了峰值算力,看 PE 的平均利用率 >> 负载均衡
- SOTA网络模型的运行时间 >> MLPerf
- 时延 Latency
- 通信时延对 MACs 的影响 >> 优化带宽
- Batch Size 大小与内存大小 >> 多级缓存设计
- 能耗 Energy
- 执行SOTA网络模型时候 Ops/W >> 部署场景
- 内存读写功耗 (e.g., DRAM) >> 降低能耗
- 系统价格 System Cost
- 片内多级缓存 Cache 大小 >> 内存设计
- PE 数量、芯片大小、纳米制程 >> 电路设计
- 易用性 Flexibility
- 对主流AI框架支持度 (PyTorch) >> 软件栈
附录
PPT
https://github.com/chenzomi12/DeepLearningSystem
第一篇章
合集·【AI框架】基础概念:链接
合集·【AI框架】分布式并行策略:链接
合集·【AI编译器】传统编译器:链接
合集·【推理系统】整体概述:链接
第二篇章
合集·【AI芯片】AI计算体系:链接
合集·【AI芯片】芯片基础:链接
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 nz_nuaa@163.com