hostping解决什么问题
RDMA 通信链路简要示意:
// todo:换成图
GPU ↔️ RNIC ↔️ Switch ↔️ RNIC ↔️ GPU
(下文中所谓的 intra-host 网络则代表 GPU ↔️ RNIC 这一段。)
RDMA 在数据中心提供高吞吐、低延迟的网络。整个链路中,RNIC 带宽的发展速度很快,而 intra-host 网络的带宽发展速度与之不匹配,无法再提供足够的冗余带宽,因此后者常常成为端到端性能的瓶颈。另外,intra-host 网络的系统复杂度越来越高(pcie,内存连接,socket间总线),时常会发生突然的链路故障、其他流量占用甚至配置错误的情况(如acs等)。总之,intra-host 网络不再像我们之前认为的那样稳健,同时又缺乏监控能力和诊断能力。
intra-host 网络对分布式训练的影响非常大,单个节点的故障会降低整个系统的可用性甚至中断整个系统,因为少量的丢包就可能会导致pfc风暴。更麻烦的是这个节点会很难找,往往需要数个小时甚至数天。
(此处待补充一张图)
当大规模AI训练进行过程中每一次梯度更新都需要进行大范围的 allreduce 通信,它通常以一个 ring 环的形式进行,这意味着任意两张GPU之间的通信速度减慢都会拖慢整个 allreduce 通信域内的梯度更新速度,从而拖慢总体的训练速度。
• 关于何为pfc风暴,可参考此文学习了解:https://hurray0.com/menu/138/
我们可以简单地把根因分解为两类:网络侧、主机侧
此类问题的定界是很痛苦的,因为无论是哪一侧都没一个很好的自证清白的手段!而 hostping 就是要帮助主机侧完成自证清白的工作。
当前业界定位此类问题往往需要用一个“笨方法”来缩小定位范围,即二分法。据我个人了解很多大厂还在持续使用此方法,或作为主力方案,或作为兜底方案。二分法的时间复杂度是logN,规模越大速度越慢,相对于log1的方案实在太慢。
带宽(吞吐)
主机内各种链路故障都会直接导致节点的rnic缓冲区快速累计,最终导致pfc风暴。这件事对于一台机器来说是小概率事件,但是对于一个大规模集群则是一个常见事件。另外,内核处理tcp流量会导致内存带宽(cpu-mem)被大量占用,因此会影响rdma访问主机内存的带宽。
延迟
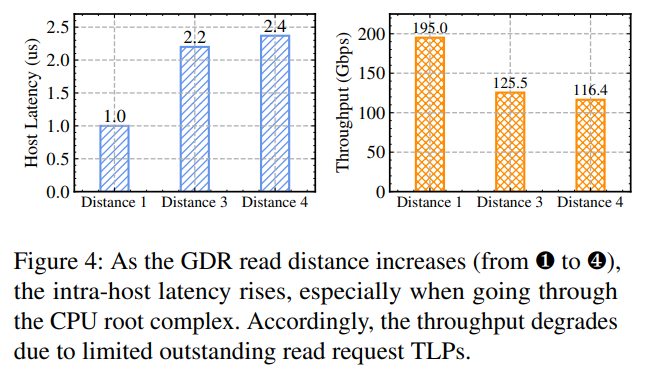
主机内部的延迟也会反过来影响主机内部带宽,原理是rnic对TLPs(Transaction Layer Packets,属于pcie的一个数据包概念)的最大未完成数量有限制,导致大量冗余的TLPs请求。论文作者使用neohost进行了一些时延影响带宽的实验,结果表明pix和pxb之间几乎没差别,但是经过了rc则严重影响时延和带宽,再加上upi这个影响会再加剧一点点,最终导致时延加了1.4微秒,带宽整整下降了40%。
• 这里有一点点疑惑,既然经过主桥的影响远小于经过rc的影响,为什么nccl保留了phb而去除了node呢?
hostping 三大挑战
- 找到尽可能统一的指标,并能高精度测量。
- 尽可能降低探测诊断过程对运行中应用的影响。
- 继续测量数据有效诊断内部主机性能瓶颈。
hostping agent 组成模块
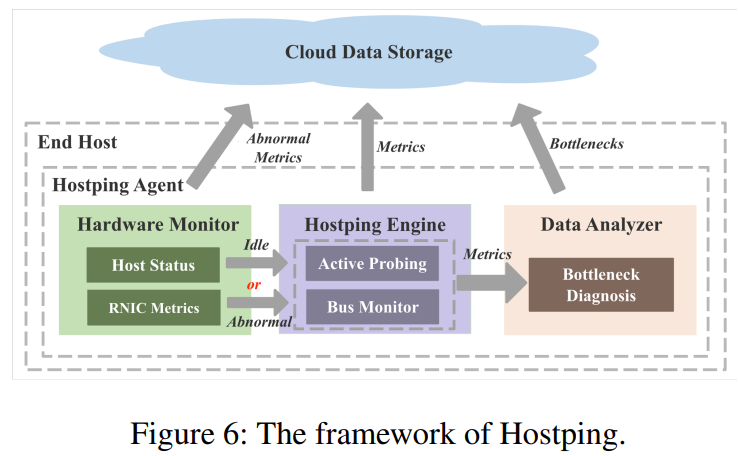
• Hardware Monitor:监控网卡和主机的异常,决定何时进行hostping
• Hostping Engine:RNIC与所有端点(gpu、mem)进行环回测试,记录时延和带宽。
• Data Analyzer:根据测试结果分析性能瓶颈点。
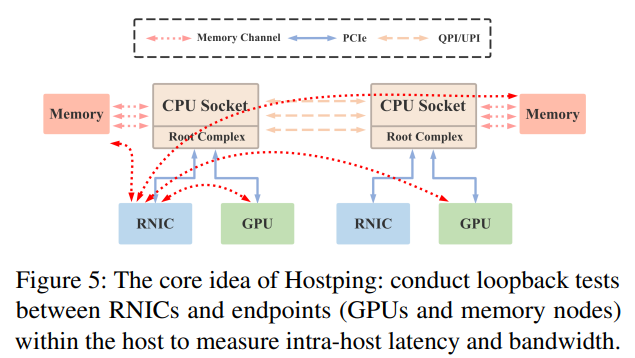
hostping 的核心思想就是在主机内部的rnic和所有端点(gpu、mem)进行环回测试,测量时延和带宽(即吞吐)。
跨平台兼容性
hostping 集成并封装了各种硬件厂商的工具(pcm、AMDuperf、nvidia-smi、neohost等),帮助运维人员在任意服务器上都能快速使用。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 nz_nuaa@163.com